Big data is the term used to describe the enormous amount of structured and unstructured data that is created and acquired from many sources. This data is characterized by its high volume, velocity, variety, and complexity. Big Data is changing how businesses extract data and insights from their data resources across a wide range of industries, including banking, healthcare, and entertainment. It includes technologies, tools and methods employed in managing, processing, analysing, and drawing insights from datasets. Through improved decision-making, improved performance, and innovation, it has revolutionised how businesses and industries work. Here are some big data tools:
1. Apache Spark
Apache Spark is a versatile open-source framework for large-scale data processing and analytics. It offers in-memory computation and aids data processing workloads including batch processing, real-time stream processing, Machine Learning, and graph processing. Its user-friendly APIs, RDDs (Resilient Distributed Datasets) and DataFrames permit developers to build complicated data workflows effortlessly.

2. Apache Flink
Apache Flink is an open-source stream processing framework for real-time data analytics and complex event processing. It aids event time processing, stateful computations, and windowing operations for diverse use instances, such as fraud detection, monitoring, and recommendation systems. Its unified batch and stream processing model permits developers to create data pipelines with low latency and high throughput.

3. Apache HBase
Apache HBase is a distributed, scalable, and consistent NoSQL database built on Hadoop HDFS. It is designed to handle massive volumes of sparse data with low latency access. It is for applications that need random, real-time read-and-write access to huge datasets and time-series data, sensor data, and log information.

4. Apache Drill
Apache Drill is a schema-free SQL query engine designed to perform interactive queries on large-scale datasets, regardless of the underlying data format. It helps several data resources, including Hadoop HDFS, NoSQL databases, and cloud storage. Its flexibility and capability to deal with semi-structured and nested data make it apt for exploring and studying several data resources without prior schema definitions.

5. Apache Beam
Apache Beam is an open-source unified programming model for batch and stream data processing. It provides an excessive-stage API for constructing data processing pipelines that can be done on processing engines, together with Apache Spark, Apache Flink, and Google Cloud Dataflow. The portability and versatility permit developers to write once and run their pipelines across execution environments.

6. Splunk
Splunk is a data analytics platform specialising in real-time tracking, searching, and analysing machine-generated data. It helps firms gain insights from several statistics resources, inclusive of logs, metrics, and events. Its effective search capabilities, visualization tools, and machine learning capabilities enable users to troubleshoot issues, detect anomalies, and make knowledgeable business decisions.

7. Apache Pig
Apache Pig is a platform for studying datasets using a high-level scripting language called Pig Latin. It eases data processing tasks on Hadoop by abstracting the underlying MapReduce operations. It lets users express data transformation and analysis in an intuitive way to process and analyse large datasets.

8. Apache Hive
Apache Hive is a warehouse infrastructure built on Hadoop providing a SQL-like query language, HiveQL, for querying and analysing large datasets saved in Hadoop HDFS. Hive interprets SQL queries into MapReduce jobs, enabling users to perform data evaluation and reporting tasks without requiring deep programming knowledge.

9. Apache Mahout
Apache Mahout is an open-source machine learning library providing algorithms and tools for scalable and distributed machine learning on massive data structures like Hadoop. It offers algorithms for tasks consisting of clustering, classification, recommendation, and collaborative filtering for organizations to offer effective machine learning solutions at any scale.

10. KNIME
KNIME (Konstanz Information Miner) is an open-source platform for data analytics, reporting, and integration. It offers a visible workflow where users can layout and execute data processing and analysis. Its modular structure and series of pre-built components make it apt for creating complicated data workflows.

11. DataRobot
DataRobot is an automated machine learning platform that aids organizations to build, deploy, and manage machine learning models. It automates the end-to-end process of feature engineering, model evaluation, and hyperparameter tuning, making it apt for data scientists to create accurate predictive models.

12. Talend
Talend is an open-source data integration and ETL (Extract, Transform, Load) platform that allows firms to connect, transform and manipulate data through several sources. It offers a unified environment for designing and executing data integration jobs, permitting users to extract insights from several datasets.

13. Databricks
Databricks is a unified analytics platform that combines data engineering, data science, and machine learning competencies. Built on Apache Spark, it offers a collaborative workspace where data teams can work to process and analyse big data successfully. It simplifies the technique of building and deploying machine learning models.

14. Cloudera
Cloudera is a leading platform for data management and analytics offering tools for storing, processing, and analyzing big datasets. It offers a distribution of Hadoop with additional tools and services, making it apt for businesses to implement and manage big data solutions.

15. RapidMiner
RapidMiner is a data science platform offering several tools for data training, machine learning, and predictive analytics. It presents a visual interface for building data pipelines, developing models, and evaluating outputs. Its intuitive interface and drag-and-drop feature make it apt for data scientists and business users.

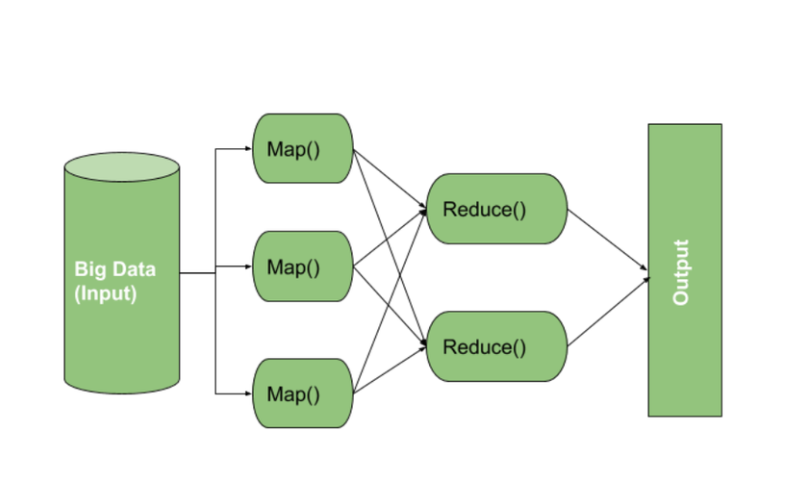
16. MapReduce
MapReduce is a programming model and processing framework for distributed and parallel processing of large datasets across a cluster of computers. It has been adopted as the foundation of Hadoop’s processing abilities. It breaks down complex data processing tasks into easier maps and reduces phases, permitting efficient computation and data transformation.
17. Impala
Impala is an open-source SQL query engine for processing data saved in Hadoop’s HDFS and HBase. It permits users to run interactive SQL queries directly on Hadoop data, presenting fast and interactive access to large datasets. It is known for its overall performance and is apt for ad-hoc querying and data exploration tasks.

18. Presto
Presto is an open-source SQL query engine for interactive and ad-hoc data analysis. It supports querying data from several resources, along with Hadoop, relational databases, and cloud storage. It is famous for its high performance and capability to address complex queries, making it a treasured tool for exploring and analysing big datasets.

19. Druid
Druid is an open-source data store and analytics engine designed for real-time data exploration and visualisation. It is for ingesting and querying time-series and event-driven data. It permits customers to conduct sub-second queries on large datasets and is utilised for building interactive dashboards and visualisations.

20. Snowflake
Snowflake is a cloud-based data warehousing platform to handle and analyse large data. It offers a scalable, cloud-native, and flexible solution for managing and querying data from several resources. Its unique architecture separating computing and storage permits users to scale their resources independently to meet their specific needs.