Machine learning is an intelligence specializing in developing models and algorithms that let computers examine from facts and anticipate or decide on matters without being explicitly programmed. It is based on the belief that computer systems can discover connections in facts and utilise that knowledge to carry out responsibilities or beautify overall performance over the years. Many pertinent and representative statistics are vital for ML systems to examine from. Datasets are important because they offer the expertise required for analysing, growing, and trying out system gaining knowledge of models. Here are a few datasets that will help you master in data analytics:
1. Uci Machine Learning Repository
The UCI Machine Learning Repository, a famous collection of datasets, is run by means of the University of California, Irvine. It offers several datasets from several disciplines, together with regression, category, clustering, and advice structures. The library is used by professionals, academics, and employees to benchmark and evaluate ML algorithms.
2. Kaggle
For machine learning and facts technology competitions, Kaggle is a well-known website. It houses a extensive collection of datasets that the establishments and the public have contributed. The datasets encompass several subjects, which include herbal language processing, photograph classification, and time collection evaluation. The platform offers sources and tools for model building, collaboration, and facts discovery.

3. U.s. Census Bureau
The United States Census Bureau offers data on demographics, economic indicators, and geographic data. Various information analysis and ML applications, like population projections, demographic research, and socioeconomic evaluation, advantage from those datasets. They may be accessed and examined by means of using facts equipment and APIs.
4. Data.gov
The open facts web page of the USA government is known as information.Gov. It has a massive series of datasets from several governmental organizations that span a lot of topics, including surroundings, transportation, health, and education.
5. Imagenet
Large-scale image databases like ImageNet are hired in computer imaginative and prescient and deep gaining knowledge of research. It has billions of tagged pictures in numerous classes. The improvement of item identification and photo categorization algorithms has been drastically used. It is a benchmark dataset used for checking out the effectiveness of different CV models.

6. Imdb
An online database known as IMDb (Internet Movie Database) gives information about films, actors, TV episodes, and other relevant details about the media enterprise. It provides datasets that can be utilised for gadget gaining knowledge of programs while being in the main regarded as a source of film information. For text-primarily based obligations like advice structures and sentiment evaluation, IMDb, as an example, provides databases of film scores and opinions.

7. Enron Email Dataset
A collection of emails despatched and acquired with the aid of personnel of the energy organisation Enron Corporation, which filed for financial ruin in 2001, is called the Enron Email Dataset. This dataset is used for research associated with email evaluation, fraud detection, and language processing. It is a valuable tool for studying community traits and developing e mail-related system mastering programs since it includes many emails and attachments.
8. Mnist
A popular dataset in CV and ML is MNIST. It has 60,000 tagged images of handwritten numerals (0–nine) and 10,000 captioned photos for checking out. It is a benchmark dataset for growing and evaluating image category algorithms. It is used to educate and control several ML models, which includes deep neural networks, for digit recognition tasks.

9. Cifar-10/Cifar-100
For picture categorization, the CIFAR-10 and CIFAR-100 datasets of tagged photograph collections are used. In contrast to CIFAR-100, which possesses a hundred lessons with 600 pictures every, CIFAR-10 includes 60,000 32×32-pixel snap shots distributed among 10 classes. They offer a hard testing environment for creating algorithms to comprehend things in snap shots correctly.

10. Stanford Large Network Dataset Collection (snap)
Network datasets from SNAP are used to research graphs, social networks, on line social media, and other forms of networks. It contains datasets from citation networks, and social networks (like Facebook and Twitter). For teachers and programmers running on social network mining, network analysis, and graph algorithms, it’s a useful resource.

11. Yelp Open Dataset
Yelp Open Dataset is a big collection of records taken from the Yelp website online and consists of consumer profiles, reviews, enterprise details, and other data. It is helpful for several studies and analytical jobs relating to enterprise insights, user behaviour, sentiment analysis, and advice systems since it covers a wide range of companies and areas. Researchers and developers can browse and examine actual-international user-generated data for ML applications.

12. Cityscapes
A dataset called as Cityscapes became generated for CV applications which include deciphering urban views and self sustaining driving. It presents notable, pixel-level annotations of town road scenes further to semantic segmentation labels, images, and different capabilities.

13. Iris
The Iris dataset is a famous dataset in pattern recognition and system getting to know. It includes measurements of the numerous traits of iris blossoms from three wonderful species. Sepal period, sepal width, petal period, and petal width are 4 traits in the dataset, alongside their respective class labels. The Iris dataset is often employed for classification and clustering tasks and is a popular for assessing how nicely ML algorithms carry out.

14. Urbansound Dataset
A series of audio recordings made in urban settings is referred to as the UrbanSound dataset. It consists of audio snippets of many metropolitan noises, consisting of road track, sirens, drilling, and automobile horns. Each recording in the collection is recognized via a class label that identifies the form of sound.

15. Pascal Voc Dataset
A popular dataset for item recognition and identity in CV is Pascal VOC (Visual Object Classes). Numerous pictures from numerous object classes are blanketed with the elegance descriptions and matching item bounding bins. The dataset facilitates within the development of item recognition techniques by means of serving as a baseline for assessing item detection.

16. Amazon Aws Public Datasets
A series of freely accessible datasets from Amazon Web Services (AWS) spans numerous topics, which includes biology, economics, and climatology. Researchers, builders, and records scientists may additionally get entry to those datasets for analysis and gadget learning due to the AWS platform, which hosts them.

17. Openml
Good sized quantities of ML datasets are available on the open-source platform referred to as OpenML. Users may explore, download, and change datasets for several ML programs from one commonplace repository. A huge variety of datasets, inclusive of regression, clustering, classification, and greater, is obtainable by it. Additionally, the platform consists of collaborative talents that allow its customers to feature to experiments, dataset annotations, and tests.
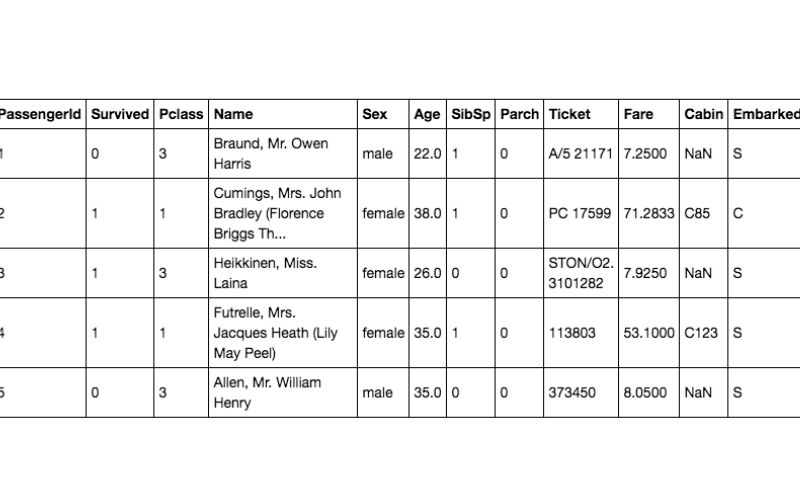
18. Titanic
A common beginner-level dataset for training classification systems is the Titanic dataset. It encompasses info at the passengers on board the RMS Titanic, which include price tag type, age, gender, and survival degree. Based on the information handy, the mission commonly involves guessing whether or not or not a passenger survived.
19. Boston Housing
The dataset for Boston Housing is utilized in ML and regression analysis. It consists of info on housing charges inside the Boston vicinity and different traits just like the crime fee, the standard wide variety of rooms in keeping with domestic, and the distance to activity hubs. Regression tasks aim to forecast the median value of owner-occupied homes in various neighbourhoods based on the given attributes, frequently employ the dataset.

20. Reddit Comments
Reddit Comments dataset possesses remarks from the popular social media platform Reddit. It has several user-generated comments from different subreddits that deal with several subjects. The dataset can be used for textual content classification, sentiment analysis, Natural language processing (NLP), and different ML responsibilities related to textual content.


Top 20 Datasets To Practice Data Analytics
Machine learning is an intelligence specializing in developing models and algorithms that let computers examine from facts and anticipate or decide on matters without being explicitly programmed. It is based on the belief that computer systems can discover connections in facts and utilise that knowledge to carry out responsibilities or beautify overall performance over the years. Many pertinent and representative statistics are vital for ML systems to examine from. Datasets are important because they offer the expertise required for analysing, growing, and trying out system gaining knowledge of models. Here are a few datasets that will help you master in data analytics:
1. Uci Machine Learning Repository
The UCI Machine Learning Repository, a famous collection of datasets, is run by means of the University of California, Irvine. It offers several datasets from several disciplines, together with regression, category, clustering, and advice structures. The library is used by professionals, academics, and employees to benchmark and evaluate ML algorithms.
2. Kaggle
For machine learning and facts technology competitions, Kaggle is a well-known website. It houses a extensive collection of datasets that the establishments and the public have contributed. The datasets encompass several subjects, which include herbal language processing, photograph classification, and time collection evaluation. The platform offers sources and tools for model building, collaboration, and facts discovery.
3. U.s. Census Bureau
The United States Census Bureau offers data on demographics, economic indicators, and geographic data. Various information analysis and ML applications, like population projections, demographic research, and socioeconomic evaluation, advantage from those datasets. They may be accessed and examined by means of using facts equipment and APIs.
4. Data.gov
The open facts web page of the USA government is known as information.Gov. It has a massive series of datasets from several governmental organizations that span a lot of topics, including surroundings, transportation, health, and education.
5. Imagenet
Large-scale image databases like ImageNet are hired in computer imaginative and prescient and deep gaining knowledge of research. It has billions of tagged pictures in numerous classes. The improvement of item identification and photo categorization algorithms has been drastically used. It is a benchmark dataset used for checking out the effectiveness of different CV models.
6. Imdb
An online database known as IMDb (Internet Movie Database) gives information about films, actors, TV episodes, and other relevant details about the media enterprise. It provides datasets that can be utilised for gadget gaining knowledge of programs while being in the main regarded as a source of film information. For text-primarily based obligations like advice structures and sentiment evaluation, IMDb, as an example, provides databases of film scores and opinions.
7. Enron Email Dataset
A collection of emails despatched and acquired with the aid of personnel of the energy organisation Enron Corporation, which filed for financial ruin in 2001, is called the Enron Email Dataset. This dataset is used for research associated with email evaluation, fraud detection, and language processing. It is a valuable tool for studying community traits and developing e mail-related system mastering programs since it includes many emails and attachments.
8. Mnist
A popular dataset in CV and ML is MNIST. It has 60,000 tagged images of handwritten numerals (0–nine) and 10,000 captioned photos for checking out. It is a benchmark dataset for growing and evaluating image category algorithms. It is used to educate and control several ML models, which includes deep neural networks, for digit recognition tasks.
9. Cifar-10/Cifar-100
For picture categorization, the CIFAR-10 and CIFAR-100 datasets of tagged photograph collections are used. In contrast to CIFAR-100, which possesses a hundred lessons with 600 pictures every, CIFAR-10 includes 60,000 32×32-pixel snap shots distributed among 10 classes. They offer a hard testing environment for creating algorithms to comprehend things in snap shots correctly.
10. Stanford Large Network Dataset Collection (snap)
Network datasets from SNAP are used to research graphs, social networks, on line social media, and other forms of networks. It contains datasets from citation networks, and social networks (like Facebook and Twitter). For teachers and programmers running on social network mining, network analysis, and graph algorithms, it’s a useful resource.
11. Yelp Open Dataset
Yelp Open Dataset is a big collection of records taken from the Yelp website online and consists of consumer profiles, reviews, enterprise details, and other data. It is helpful for several studies and analytical jobs relating to enterprise insights, user behaviour, sentiment analysis, and advice systems since it covers a wide range of companies and areas. Researchers and developers can browse and examine actual-international user-generated data for ML applications.
12. Cityscapes
A dataset called as Cityscapes became generated for CV applications which include deciphering urban views and self sustaining driving. It presents notable, pixel-level annotations of town road scenes further to semantic segmentation labels, images, and different capabilities.
13. Iris
The Iris dataset is a famous dataset in pattern recognition and system getting to know. It includes measurements of the numerous traits of iris blossoms from three wonderful species. Sepal period, sepal width, petal period, and petal width are 4 traits in the dataset, alongside their respective class labels. The Iris dataset is often employed for classification and clustering tasks and is a popular for assessing how nicely ML algorithms carry out.
14. Urbansound Dataset
A series of audio recordings made in urban settings is referred to as the UrbanSound dataset. It consists of audio snippets of many metropolitan noises, consisting of road track, sirens, drilling, and automobile horns. Each recording in the collection is recognized via a class label that identifies the form of sound.
15. Pascal Voc Dataset
A popular dataset for item recognition and identity in CV is Pascal VOC (Visual Object Classes). Numerous pictures from numerous object classes are blanketed with the elegance descriptions and matching item bounding bins. The dataset facilitates within the development of item recognition techniques by means of serving as a baseline for assessing item detection.
16. Amazon Aws Public Datasets
A series of freely accessible datasets from Amazon Web Services (AWS) spans numerous topics, which includes biology, economics, and climatology. Researchers, builders, and records scientists may additionally get entry to those datasets for analysis and gadget learning due to the AWS platform, which hosts them.
17. Openml
Good sized quantities of ML datasets are available on the open-source platform referred to as OpenML. Users may explore, download, and change datasets for several ML programs from one commonplace repository. A huge variety of datasets, inclusive of regression, clustering, classification, and greater, is obtainable by it. Additionally, the platform consists of collaborative talents that allow its customers to feature to experiments, dataset annotations, and tests.
18. Titanic
A common beginner-level dataset for training classification systems is the Titanic dataset. It encompasses info at the passengers on board the RMS Titanic, which include price tag type, age, gender, and survival degree. Based on the information handy, the mission commonly involves guessing whether or not or not a passenger survived.
19. Boston Housing
The dataset for Boston Housing is utilized in ML and regression analysis. It consists of info on housing charges inside the Boston vicinity and different traits just like the crime fee, the standard wide variety of rooms in keeping with domestic, and the distance to activity hubs. Regression tasks aim to forecast the median value of owner-occupied homes in various neighbourhoods based on the given attributes, frequently employ the dataset.
20. Reddit Comments
Reddit Comments dataset possesses remarks from the popular social media platform Reddit. It has several user-generated comments from different subreddits that deal with several subjects. The dataset can be used for textual content classification, sentiment analysis, Natural language processing (NLP), and different ML responsibilities related to textual content.
Top 20 Low Internet Users Apps On Mobile
Next PostTop 20 IEEE Protocols
Related Posts
The Best NPS Tools For Enhancing Customer Satisfaction
The Best Knowledge Management Tools For Efficient Collaboration And Information Sharing
The Best Website Optimization Tools For Boosting Performance And User Experience
The Best Security Orchestration, Automation, And Response (SOAR) Tools
The Best Employee Timesheet Tools For Efficient Time Tracking And Management
Articles
The Best NPS Tools For Enhancing Customer Satisfaction
Businesses utilize the Net Promoter Score (NPS), a widely accepted statistic, to assess customer happiness and loyalty to them. This...
Read moreThe Best Knowledge Management Tools For Efficient Collaboration And Information Sharing
In today's fast-paced era, having access to knowledge is crucial for organizations. Effective knowledge management is for organizations of all...
Read moreThe Best Website Optimization Tools For Boosting Performance And User Experience
Website optimization tools achieve this goal by helping businesses analyze, improve, and maintain their websites to ensure optimal performance and...
Read moreThe Best Security Orchestration, Automation, And Response (SOAR) Tools
The increasing complexity and volume of cyber threats have made it necessary to implement security measures. Security Orchestration, Automation, and...
Read moreThe Best Employee Timesheet Tools For Efficient Time Tracking And Management
Employee time-tracking tools play a role in today's businesses. They aid organizations in monitoring and overseeing employee hours, ensuring invoicing,...
Read moreAndroid
Top 20 Best 4G Phones
The evolution of communication technologies has been a transformative journey, advancing from basic forms of communication to complex and interconnected...
Read moreTop 20 Sites To Host Websites
Modes of Communication have changed over the years. The Internet has become the fastest means of communication. The speed and...
Read moreTop 20 Keyword Research Tools
To have success in SEO strategy, keyword research is the boss. Without good keyword research, ranking high on search engines...
Read moreTop 20 Mind Games For Android Users
In today’s digital era, where smartphones have become one of the essential parts of our lives, almost 80% of today's...
Read moreTwenty Rare Phones in the World
The evolution of mobile phones has been remarkable from easy communication devices to effective pocket-sized computers. Alongside their generational advancements,...
Read moreiPhone
20 Facts About iPhone You Don’t Know
iPhone is one of the best-selling products worldwide; it needs no introduction. Apple Inc. developed a line of smartphones, which...
Read moreGadgets
Top 20 Keyword Research Tools
To have success in SEO strategy, keyword research is the boss. Without good keyword research, ranking high on search engines...
Read moreTwenty Rare Phones in the World
The evolution of mobile phones has been remarkable from easy communication devices to effective pocket-sized computers. Alongside their generational advancements,...
Read moreTop 20 Printers In Use
Printers are crucial devices used to produce hard copies of documents, pictures, and other digital content. When deciding on a...
Read moreTop 20 Ways In Which Human-Computer Interaction Will Be Beneficial
Design and research are done in the field of human-computer interaction (HCI) to show and understand how humans will interact...
Read moreTop 20 Essential Gadgets For Smartphones
Modern-day mobile phones are great. They have plenty of advanced features, but when a customer unboxes the smartphone, they get...
Read more