Database stores data related to several domains such as finance, education, e-commerce, healthcare, etc. They are a vital part of the contemporary computer-based applications managing large volumes of data efficiently. One type of database is the NoSQL database, short for “Not Only SQL” or “non-relational databases,” which represents a category of database management systems that are different from traditional relational databases. They offer the limitations of relational databases, which struggle with the flexibility required for modern applications. They have gained immense fame in recent years as they handle unstructured or semi-structured data. Here are some of the features of NoSQL Databases:
1. Schemaless
Schemaless is a fundamental feature of NoSQL databases where data is stored without a predefined schema. Unlike traditional relational databases where the data structure is defined, NoSQL databases are more flexible, means that the fields are added or removed from data for scenarios where data structures may evolve rapidly, as in web applications.
2. Highly Scalable
The scalability of NoSQL databases scales out horizontally so that more machines or nodes can be added to the database cluster as the data and traffic grow. This horizontal scaling can handle large amounts of data and high traffic loads, making them apt for web applications and services that need to scale with demand.
3. Distributed Architecture
NoSQL databases are built on distributed architectures, which distribute data across multiple nodes or servers. This distribution provides benefits such as fault tolerance (the ability to recover from hardware failures), load balancing (evenly distributing traffic), and improved performance through parallel processing.
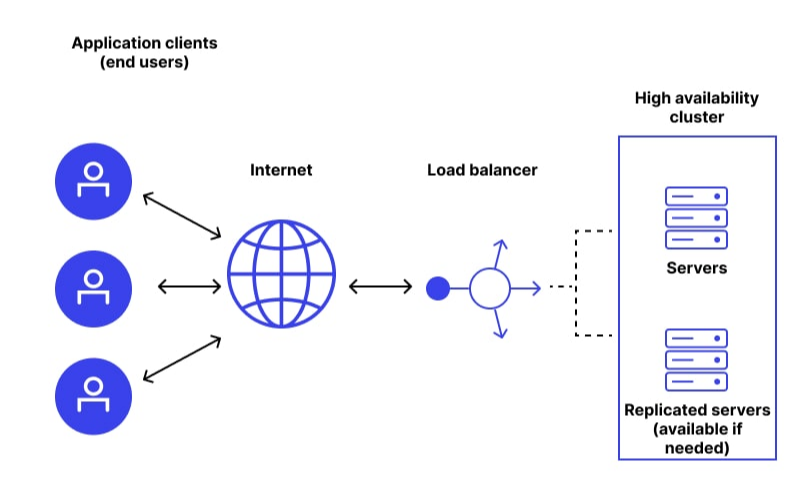
4. High Availability
High availability is crucial for applications that require constant uptime. NoSQL databases offer functionalities such as data replication and distributed architectures, ensuring that data is always available even during node failure. This feature is highly apt for mission-critical applications.
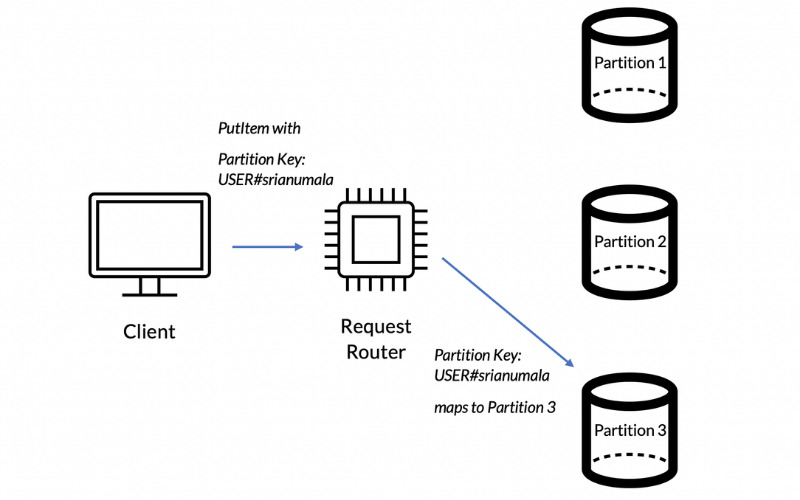
5. Partitioning
Partitioning in NoSQL databases involves splitting large datasets into smaller, more manageable partitions or shards. Each shard can be stored on a different node, allowing efficient data distribution. Partitioning improves query performance and enables databases to scale horizontally.
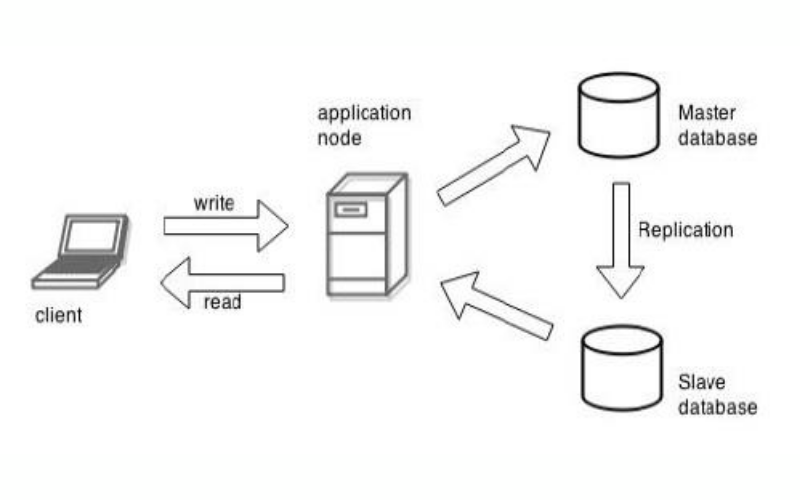
6. Replication
Replication involves creating copies of data and distributing them to multiple nodes within the database cluster. It improves data availability and fault tolerance. In case of node failure, data is still accessible from other nodes. It is used to place data closer to end-users to reduce latency.
7. Data Types
NoSQL databases support several data types, including text, numbers, dates, and geospatial data. This flexibility aids in storing and querying several data types within the same database, accommodating diverse application needs.
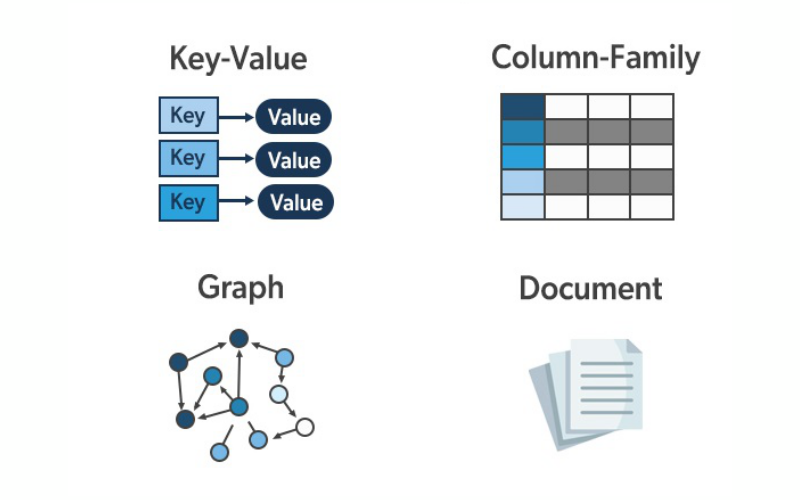
8. Document-Oriented
Document-oriented NoSQL databases store, retrieve and manage semi-structured or unstructured data as documents. Each document contains data in a self-contained unit like JSON or XML and doesn’t require a fixed schema. Document-oriented databases are highly flexible as documents of different structures are stored in the same database.

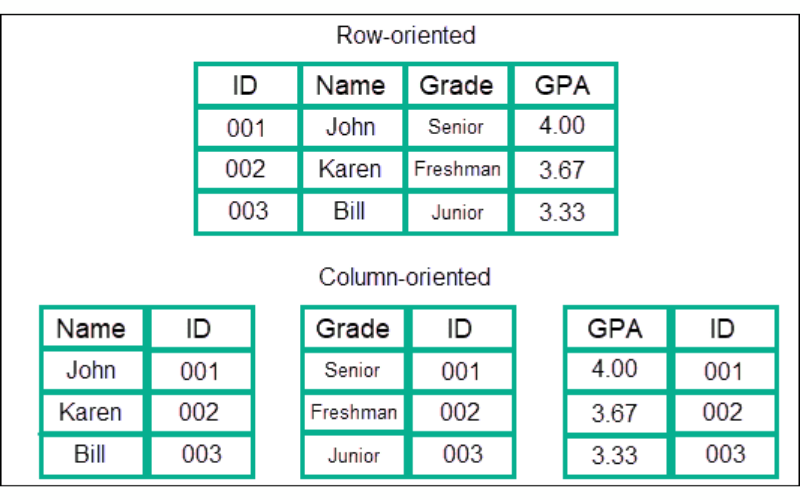
9. Column-Family Stores
Column-family stores organise data into “column families” or “column families and super columns”. This schema design is apt for applications which require reading and writing large amounts of data and applications with sparse or dynamic schemas.
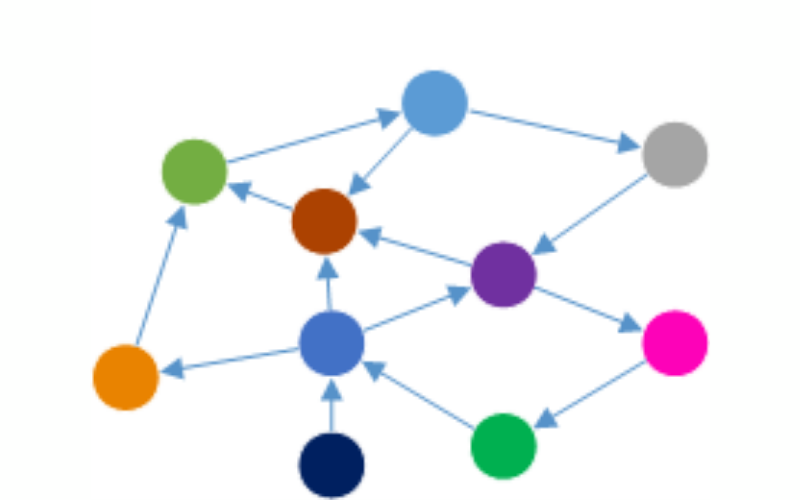
10. Graph Databases
Graph databases handle data having complex relationships for applications like recommendation engines, social networks, and fraud detection. They utilise graph structures to represent and query relationships between data points efficiently.
11. Full-Text Search
Full-text search databases are optimized for searching and querying textual data. They provide fast and accurate search results, making them apt for extensive text-searching applications like e-commerce platforms and content management systems.
12. Geo-Spatial Indexing
Geo-spatial indexing handles location-based data. It enables storage and retrieval of data points with geo-spatial attributes, making it apt for mapping, geolocation services, and location-based analytics.
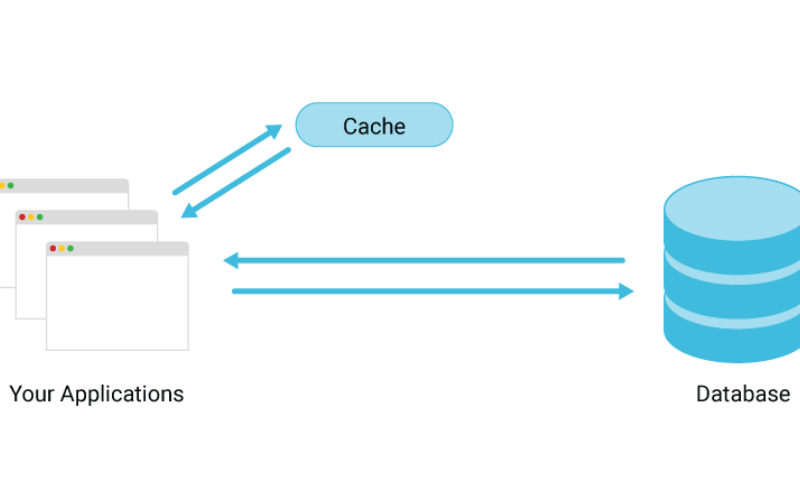
13. Caching
Caching enhances data retrieval speed. By storing frequently accessed data in memory or a cache layer, databases can reduce the need to access slower storage devices or perform complex computations to fetch the data. It results in significantly lower query latency and improved application performance.
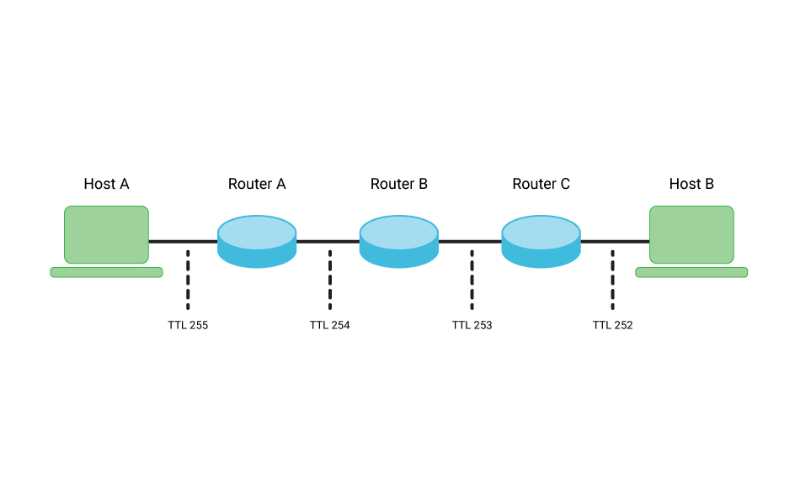
14. TTL (Time-To-Live)
Time-to-live (TTL) feature sets the expiration time for data stored in the database. Once the TTL expires, the data is removed from the database automatically. It aids in managing transient or temporary data like session tokens, cached data, or logs. It ensures that data is purged when it is no longer needed, aid in optimizing database storage and maintain data cleanliness.
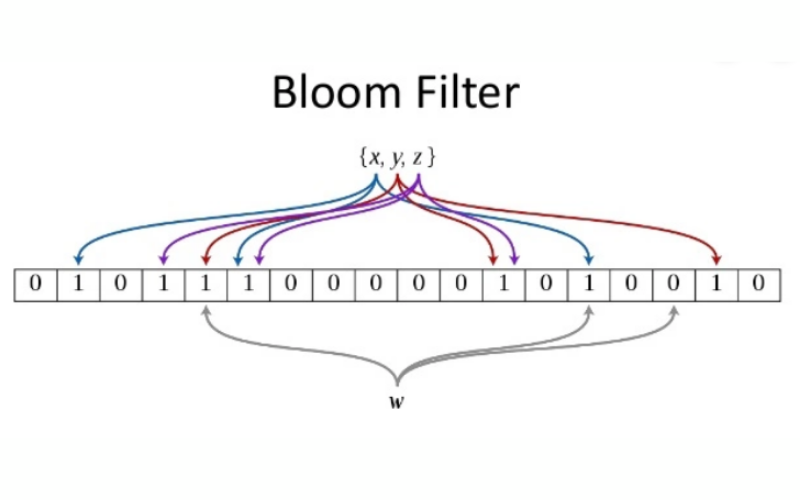
15. Bloom Filters
Bloom filters are probabilistic data structures used in some NoSQL databases to quickly test whether an element is a member of a set or not. They offer fast membership queries with a controlled rate of false positives. It is valuable for tasks like checking if a particular key exists in a massive dataset without the need for expensive disk or network operations. Bloom filters are space-efficient and can reduce query times for certain types of applications.
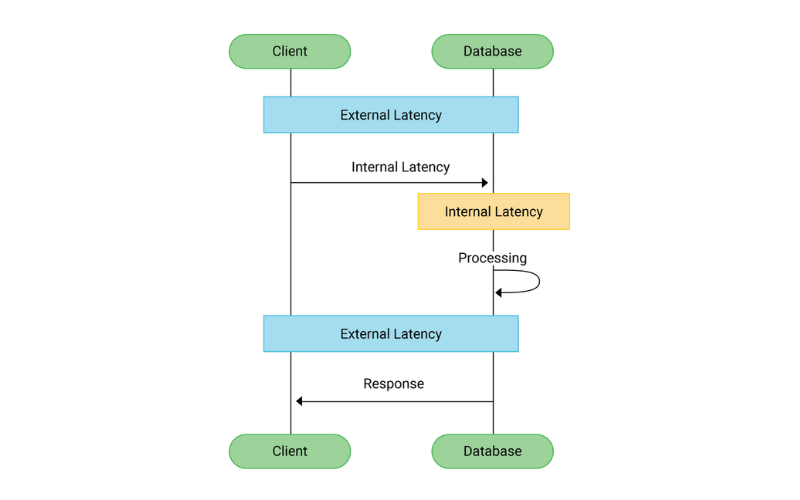
16. Low Latency
Low latency is a crucial feature for applications that require real-time or near-real-time data access. These databases minimize the time it takes to retrieve data, ensuring that query response times remain fast consistently, even as data volumes increase. They are used in gaming, financial services, and IoT platforms where speed is of the essence.
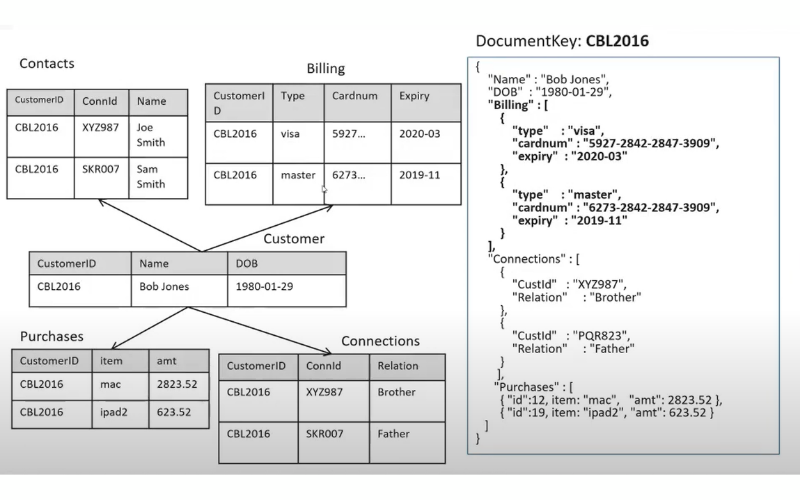
17. JSON Support
JSON (JavaScript Object Notation) is a widely used data interchange format, and many NoSQL databases offer native support for storing and querying JSON data. It simplifies data modelling and makes it easier to work with semi-structured data, as JSON documents are stored natively without requiring a predefined schema.
18. Multi-Model Support
Multi-model databases can accommodate different data models within the same database system. It uses several data models like document, key-value, graph, or relational in a single database, permitting one to choose the most suitable model for each data type or use case. It offers greater flexibility and addresses several application requirements without resorting to multiple databases.
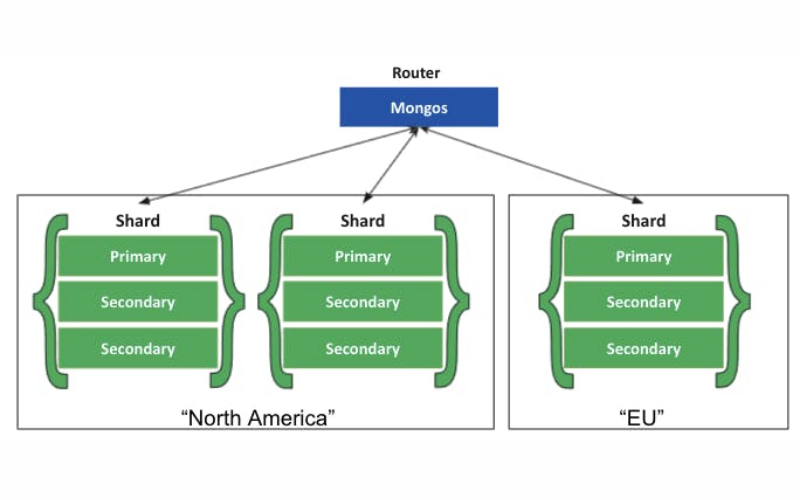
19. Auto-Sharding
Auto-sharding is a fundamental feature designed to horizontally partition data across multiple nodes or servers automatically. Here, data is divided into smaller subsets called “shards,” and each shard is stored on a different node or server. It is crucial for ensuring scalability and fault tolerance in distributed database systems.
20. Compression
Compression is a data optimization technique to reduce the storage footprint and improve data transfer efficiency. It encodes data compactly by eliminating redundancy or using efficient encoding algorithms.